Supervised Learning and Unsupervised Learning in Machine Learning
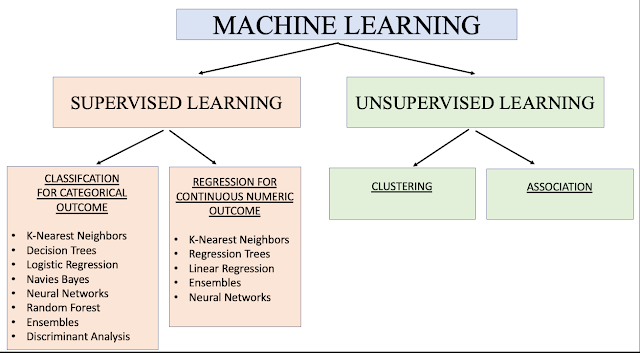
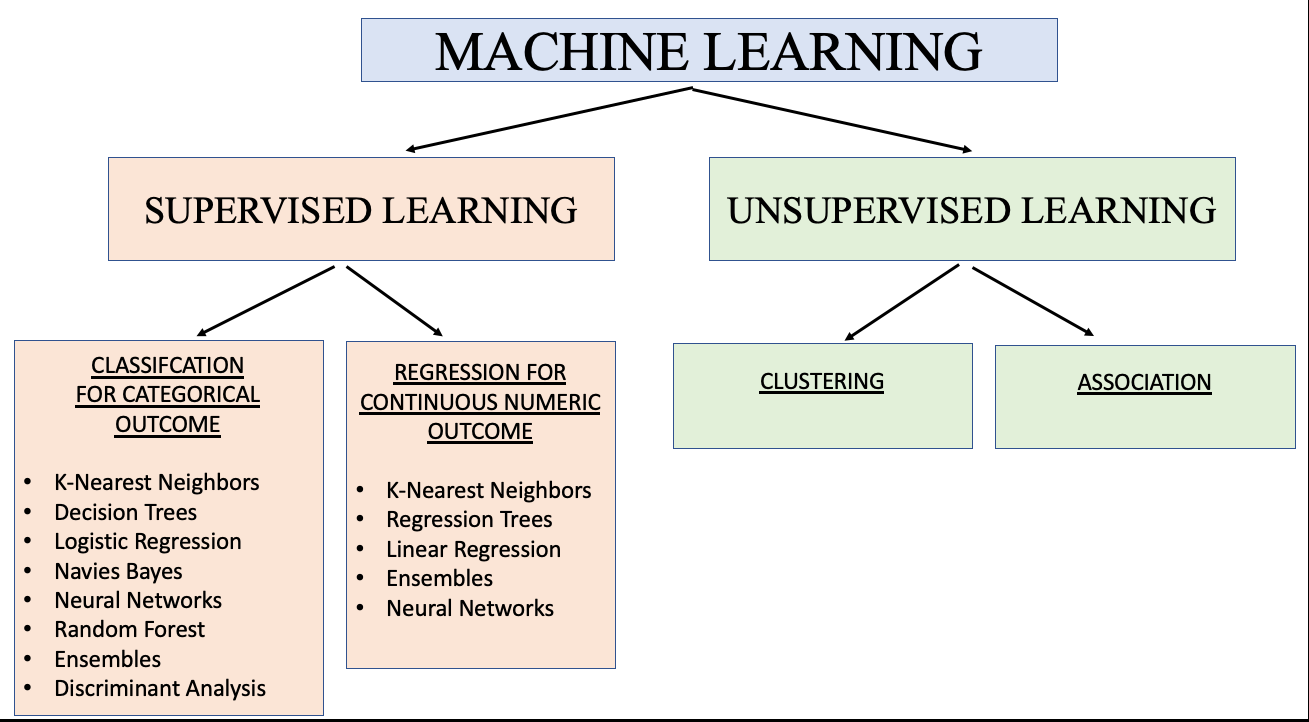
Machine learning, a subset of artificial intelligence, involves training algorithms to learn from and make predictions or decisions based on data. Two fundamental types of machine learning are supervised learning and unsupervised learning. Understanding these concepts is crucial for anyone diving into the world of data science and machine learning.
Supervised Learning

Key Concepts
Labeled Data: In supervised learning, the dataset consists of input-output pairs. For example, a dataset for a spam detection algorithm might include emails (inputs) and labels indicating whether each email is spam or not (outputs).
Training Process: The algorithm uses the labeled data to learn the relationship between inputs and outputs. This process involves minimizing a loss function, which measures the difference between the predicted output and the actual output.
Common Algorithms:
- Linear Regression: Used for predicting continuous values.
- Logistic Regression: Used for binary classification problems.
- Decision Trees: Used for classification and regression tasks.
- Support Vector Machines (SVM): Used for classification and regression tasks.
- Neural Networks: Used for complex tasks like image and speech recognition.
Applications
- Spam Detection: Classifying emails as spam or not spam.
- Image Classification: Identifying objects in images.
- Speech Recognition: Converting spoken language into text.
- Medical Diagnosis: Predicting diseases based on patient data.
Unsupervised Learning

Unsupervised learning, in contrast, involves training a model on data without labeled responses. The goal is to find hidden patterns or intrinsic structures in the input data.
Key Concepts
Unlabeled Data: In unsupervised learning, the dataset consists only of input data without corresponding output labels. The algorithm tries to learn the structure from the data.
Training Process: The algorithm explores the data to find patterns and relationships. This often involves clustering data points into groups or reducing the dimensionality of the data.
Common Algorithms:
- K-Means Clustering: Partitions data into K distinct clusters based on feature similarity.
- Hierarchical Clustering: Builds a tree of clusters.
- Principal Component Analysis (PCA): Reduces the dimensionality of data while preserving most of the variance.
- Anomaly Detection: Identifies outliers in the data.
Applications
- Customer Segmentation: Grouping customers based on purchasing behavior.
- Market Basket Analysis: Finding associations between products in transaction data.
- Anomaly Detection: Detecting unusual transactions that might indicate fraud.
- Recommendation Systems: Recommending products based on user behavior.
Key Differences
- Data Requirements: Supervised learning requires labeled data, while unsupervised learning works with unlabeled data.
- Objective: Supervised learning aims to predict outcomes for new data, while unsupervised learning seeks to uncover hidden patterns in data.
- Common Use Cases: Supervised learning is often used for predictive tasks, whereas unsupervised learning is used for exploratory data analysis.
Conclusion
Both supervised and unsupervised learning play crucial roles in the field of machine learning. Supervised learning is powerful for prediction and classification tasks where labeled data is available. Unsupervised learning, on the other hand, is invaluable for discovering hidden patterns and structures in data. By understanding these two approaches, data scientists and machine learning practitioners can choose the right method for their specific needs and continue to push the boundaries of what machines can learn and accomplish.
Sithija Theekshana
(bsc in Computer Science and Information Technology)
(bsc in Applied Physics and Electronics)
linkedin ;- www.linkedin.com/in/sithija-theekshana-008563229
Comments
Post a Comment